
AI競爭核心轉向數據,Aralia讓數據在保有主權下跨域共享,符合FAIR原則實現AI的決策價值。
為何AI 投資仍卡在數據處理? —— 談未來的數據基礎架構
BigObject 共同創辦人薛文蔚博士於 2024 年指出:「AI 時代的競爭,決戰於數據」。
回頭看近幾年的發展,這個觀點其實正逐步被驗證。當大家都在談模型能力與算力規模時,真正拉開差距的,往往不是模型本身,而是 —— 誰能取得更即時、更全面、可信任、且可直接使用的數據。
現實的落差:AI 很強,但數據還在卡關
但回到現實,多數組織在數據使用上,仍面臨幾個根本問題:
▪️ 數據分散在不同系統與平台
▪️ 數據共享涉及信任與主權問題
▪️ 使用者仍需重複蒐集、清洗、整合,數據準備成本高
這些結構性的限制,使得數據難以共享,也因此不夠即時、也不夠全面,讓 AI 的潛力難以完全發揮。結果就是 AI 很強,但數據還在卡關。
問題的本質:數據還沒準備好給 AI 使用
這也帶出一個更核心的問題:
即使數據存在,如果它仍停留在「人類可讀」的形式 (如未經結構化的 PDF 或報告文本),而不是「可被 AI 直接使用」的狀態 (如具備標準標籤、可供機器即時運算的數據格式),那麼 AI 的能力,終究只能建立在不完整且低效率的基礎之上。
更關鍵的是,AI 要能做出有效決策,需要的不是「曾經的數據」,而是「當下的數據」— 即時、持續更新、並能反映真實世界狀態的資訊。
同時,AI 的判斷也不應只依賴單一來源,而是需要參考跨領域、多面向的數據。例如在規劃大型活動的人潮疏散時,必須同時考慮天氣、交通、道路狀況、活動型態與參與族群等因素,而不是依賴單一數據做判斷。
換句話說,AI 的瓶頸,不在模型,也不是數據不夠,而是當下的數據「Not AI-Ready」。
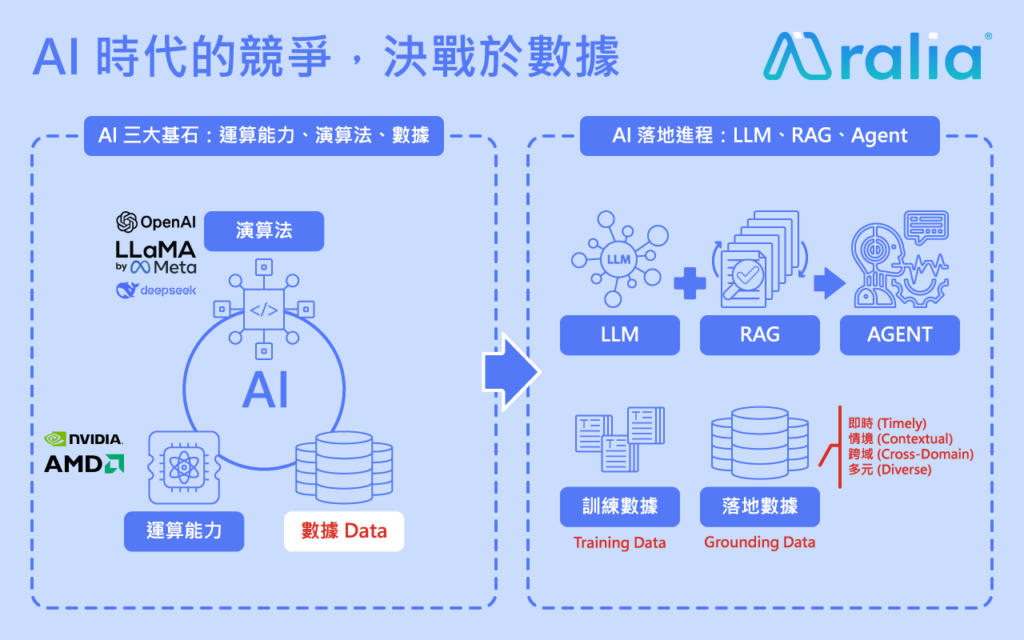
趨勢轉變:從「模型競爭」走向「數據可用」,再到「數據流動」
在這樣的背景下,一個新的趨勢正逐漸成形:競爭,不只是誰有模型,而是誰能讓數據真正流動起來。
這也是為什麼,近年來無論是 Data Space,或開放數據生態系的發展,都開始聚焦在同一個核心問題:如何讓數據在不同組織之間流通,同時仍保有控制與信任機制?
因為只有當數據能在可信的環境中跨域流動,並被持續更新與使用,AI 才有可能真正建立在完整且動態的資訊基礎之上。
AI 的戰場,正在轉向數據基礎設施
當模型逐漸標準化,真正決定競爭力的,將是背後支撐 AI 的數據環境。
意味著,一個好的數據基礎設施,不只是讓數據被儲存或管理,而是能夠支撐數據安全的跨域共享與使用,讓不同組織不需要重複建置系統、重複下載與清洗數據,就能在既有資料基礎上進行協作與決策。
新一代架構正從「封閉式儲存」轉向「去中心化共享流動」。Aralia AI-Ready Data Ecosystem,正是在這樣的脈絡下提出的一種實踐方式:
在不需下載數據的前提下,讓數據能在信任機制下跨域使用,同時降低成本,並使數據更直接服務於AI 決策與應用。
這不僅是技術上的演進,也代表數據治理模式的轉變,並呼應國際上常提到的 FAIR 原則:
▪️ Findable (可查找):數據可以被發現與定位
▪️ Accessible (可取得):在授權機制下可被安全存取
▪️ Interoperable (可互通):可跨系統、跨領域整合使用
▪️ Reusable (可再使用):數據能被持續重複利用並產生價值
未來 AI 決戰的關鍵,將不只是「擁有數據」,而是:
如何在保有主權與信任的前提下,讓數據符合 FAIR 原則,真正被 AI 使用。
這也將成為數據經濟能否成立的基礎。
延伸閱讀
薛文蔚觀點:AI 時代的競爭,決戰於數據
https://www.storm.mg/article/5256454





